| Сегодня 12 апреля, воскресенье |
|
|
|
Какой рейтинг вас больше интересует?
|
Главная /
Каталог блоговCтраница блогера Блог Яндекса/Записи в блоге |
|
Блог Яндекса
Голосов: 7 Адрес блога: http://company.yandex.ru/blog/ Добавлен: 2007-12-13 21:24:18 блограйдером Luber |
|
Что вы видите на этой картинке?
2015-03-25 13:11:19 (читать в оригинале)Распознавание изображений — одна из самых сложных задач для компьютера. Мы уже рассказывали о том, как устроено компьютерное зрение и как оно применяется в наших сервисах — например, при поиске похожих изображений в Яндекс.Картинках. Теперь технология компьютерного зрения работает и в Яндекс.Диске — благодаря ей вы можете найти изображения форматов JPEG, GIF и PNG, содержащие текст поискового запроса. Достаточно ввести в поисковую строку нужное слово, и система найдёт на Диске картинки, на которых оно встретится. В результатах поиска вы увидите изображения с этим словом, документы, в тексте которых оно содержится, а также файлы и папки, в названиях и описаниях которых есть это слово.
Когда на Диске тысячи фотографий, разложенных по разным папкам, поиск по текстам позволит быстро найти среди них нужную. Например, скан договора с названием вроде scan723.JPG или фотографию визитки человека, с которым понадобилось связаться. Искать можно не только документы, но и любые фотографии, которые сделаны для того, чтобы сохранить текст, будь то объявление на двери подъезда или любопытный рекламный плакат в метро.
В основе поиска текстов на изображениях лежит технология оптического распознавания символов. Систем распознавания, опирающихся на эту технологию, много, и все они разные. Какие-то решают определённую задачу, например распознают партитуры, какие-то работают только с чистым текстом. Для Яндекс.Диска мы разработали свою универсальную систему, способную распознавать текст на картинках разных по виду, содержанию и, главное, качеству.
Система состоит из двух частей — классификатора картинок и модуля распознавания. Сначала классификатор, глубокая нейронная сеть, отбирает из всех картинок те, на которых изображён текст. Он учится отличать их от прочих на огромной базе изображений. Использование машинного обучения позволяет добиться высокого качества распознавания — ведь алгоритм опирается не на какие-то вручную заданные правила, а на опыт анализа миллионов разных картинок. Когда изображения с текстом отобраны, алгоритм находит на них линии, предположительно содержащие текст, — различать их помогает ещё одна нейронная сеть. На следующем этапе алгоритм оставляет только те линии текста, в которых он уверен.

Затем модуль распознавания разбивает линии текста на отдельные символы. Для каждого символа алгоритм выбирает несколько наиболее вероятных варинтов распознавания среди известных ему. Например, это могут быть буквы «О», «о» и цифра «0», очень похожие друг на друга. После этого в дело вступает языковая модель — алгоритм принимает решение, какой из символов-кандидатов подходит лучше всего. Языковая модель опирается на словари и учитывает не только сходство символов с теми, что знает система, но и контекст, то есть соседние символы. Если из нескольких вероятных символов складывается известное системе слово, то она может принять решение, что на картинке написано именно оно. Даже если некоторые символы-кандидаты в этом слове менее вероятны, чем другие.

Конечно, точность распознавания текста (а значит, и успех поиска) зависит от типа изображения, его чёткости, фона, на котором находится текст, и многих других факторов. Поэтому для разных видов изображений она разная. Например, для отсканированных документов точность распознавания текстов на русском языке составляет около 80%, для фотографий с надписями — 63,2%, а для скриншотов приближается к 100%. Помимо русского языка, система также распознаёт английский, украинский и турецкий. Точность распознавания текстов всего потока изображений более 70%. Это неплохой результат, но мы будем работать над его улучшением.
Браузер. Бета
2015-03-24 17:05:26 (читать в оригинале)Почти четыре месяца назад, в конце ноября 2014 года, мы выпустили альфа-версию нового Яндекс.Браузера. Когда речь идёт о программном обеспечении, слово «альфа» означает предварительную версию. Это не готовый продукт, а скорее опытный образец. Альфа-версию можно сравнить с наброском картины: общий замысел художника понятен, но работы предстоит ещё очень много.
Обычно альфа-версии используются для закрытого тестирования: программу дают попробовать ограниченному числу испытателей-добровольцев, которые потом высказывают своё мнение. Мы, однако, решили открыть альфа-версию нового Яндекс.Браузера для всех желающих. У нас скопилось много идей о том, каким должен быть браузер будущего, и мы рассчитывали поделиться этими идеями с вами — чтобы послушать, что вы скажете в ответ.
Расчёт оказался верным: мы получили рекордное количество отзывов. Их оказалось даже больше, чем осенью 2012 года, когда вышел первый Яндекс.Браузер. Мы хотим сказать спасибо всем, кто оставлял замечания, сообщал о неполадках и вносил предложения — в блоге Яндекса, в клубе браузера, на «Хабрахабре», в социальных сетях или через форму обратной связи. Мы изучили все отзывы до единого и продолжаем работу над браузером — теперь с учётом ваших пожеланий.
С сегодняшнего дня новый Яндекс.Браузер переходит в стадию бета-тестирования. Если задачей альфа-версии было показать вам наше видение браузера будущего, то бета-версия — это следующий шаг. Её задача — сделать будущее настоящим. Это своего рода испытательный полигон, где мы будем улучшать уже сделанное и пробовать новое.
Мы объединили в одной бета-версии две разных сборки браузера: классическую и новую. После установки вы можете выбрать, в каком интерфейсе работать: в новом — с прозрачными панелями и «Изнанкой» — или в классическом интерфейсе Яндекс.Браузера.

В новый интерфейс мы внесли несколько доработок. Во-первых, обновился механизм работы со вкладками. Отыскать вкладки, которые вы открыли, но ещё не успели просмотреть, теперь стало проще — они помечаются кружком.
Во-вторых, в новом интерфейсе появились закладки. Чтобы увидеть панель закладок, нужно кликнуть по заголовку страницы или открыть новую вкладку.
Разработка браузера — это долгий, но увлекательный процесс. Если вы хотите принять в нём участие — загружайте бета-версию для Windows и OS X и не забывайте рассказывать нам о том, что вам нравится, что не очень и что вы хотели бы изменить или добавить.
Как это работает? Рекомендации в Яндекс.Музыке
2015-03-20 13:34:48 (читать в оригинале)Все люди, вне зависимости от того, какую музыку они любят и сколько часов в день проводят в наушниках, иногда сталкиваются с одной и той же проблемой: личная фонотека заслушана до дыр и хочется чего-нибудь новенького. С одной стороны, выбор огромен — музыкальные каталоги в интернете насчитывают десятки миллионов треков и пополняются каждый день. С другой стороны, сориентироваться в этом разнообразии бывает непросто: музыки много, а вы один.
С сентября 2014 года в Яндекс.Музыке работает система музыкальных рекомендаций. Она даёт ответы на вопрос «Что бы ещё послушать?». У системы есть две ключевые особенности. Во-первых, её советы персональны — то есть составляются с учётом интересов каждого конкретного пользователя. А во-вторых, система самообучается: чем больше вы слушаете музыку, тем точнее будут рекомендации.
Как выявляются предпочтения
Прежде чем советовать пользователю ту или иную музыку, необходимо составить представление о его музыкальных вкусах. Самый простой способ сделать это — посмотреть, какие треки на Яндекс.Музыке он уже послушал. Это самая важная информация для рекомендательной системы; по истории прослушиваний можно установить, каких исполнителей и какие жанры человек предпочитает. Однако чтобы составить более полную картину, неплохо ещё понимать, что ему нравится больше, а что — меньше.
Для этого мы используем дополнительные данные. Один из источников таких данных — оценки «Нравится» и «Не нравится», которые ставят пользователи. Оценку «Нравится» в Яндекс.Музыке можно ставить трекам, альбомам, исполнителям и целым музыкальным жанрам. Оценка «Не нравится» есть в жанровом радио и в радио по исполнителю: с её помощью можно отметить треки, которые пришлись не по душе.
Как правило, люди оценивают музыку, которая вызвала у них сильный эмоциональный отклик — неважно, положительный или отрицательный. Поэтому оценки довольно точно отражают пристрастия человека. Но одних оценок недостаточно: во-первых, люди ставят их далеко не всегда, а во-вторых, в шкале не хватает полутонов — есть только или «хорошо» («Нравится»), или «плохо» («Не нравится»).
Поэтому, помимо оценок и прослушиваний, мы обращаем внимание и на другие действия пользователя: пропуски треков (например, в альбоме, подборке или радио) и добавления треков в плейлисты.

Все действия мы разделяем на положительные и отрицательные. Положительные — прослушивание, оценка «Нравится», добавление в плейлист — говорят о том, что музыка нравится пользователю, а отрицательные — пропуск и оценка «Не нравится» — наоборот. Важно понимать, что действия неравнозначны: например, пользователь может пропустить трек, который в целом ему по душе, но сейчас не подходит под настроение. Поэтому каждому действию мы присваиваем вес: у оценки «Нравится» он максимальный, а у пропуска — минимальный.
Как строится прогноз
Алгоритм анализирует профиль пользователя (то есть данные о его музыкальных предпочтениях) и предсказывает, какие треки и исполнители могут ему понравиться. Кроме того, алгоритм умеет дообучаться в режиме реального времени. Каждый раз, когда вы совершаете новое действие — слушаете трек или добавляете его в плейлист, — профиль обновляется, и прогноз строится заново. Это позволяет быстро подстраиваться под вкусы и предлагать музыку, которая отвечает сегодняшнему настроению.
Делая прогноз, алгоритм также учитывает информацию о том, как связаны друг с другом объекты из каталога Яндекс.Музыки: треки, альбомы, исполнители, жанры. Благодаря этим данным можно советовать человеку новых исполнителей в его любимом жанре. Кроме того, система сравнивает профили всех пользователей Яндекс.Музыки. Это делается для того, чтобы выявить людей со схожими музыкальными предпочтениями: то, что нравится одному, может понравиться и другому.
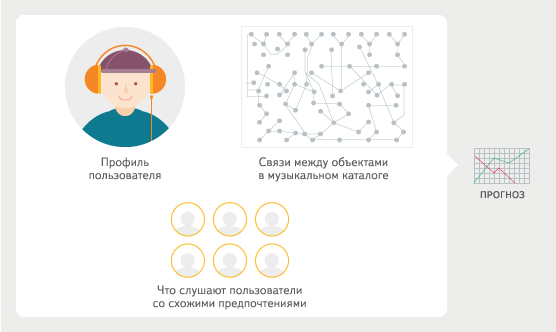
Как составляются рекомендации
Обработав данные, алгоритм выдаёт список треков и исполнителей, которые могут понравиться пользователю. Считать его окончательной рекомендацией, однако, нельзя. Во-первых, список слишком длинный — чтобы прослушать все треки, которые система выбрала за раз, не хватит и суток. Во-вторых, мы считаем, что рекомендации должны быть разнообразными: они должны включать в себя не только советы вида «раз вам понравилось X, послушайте Y», но и что-то ещё, что помогло бы сориентироваться в мире музыки — скажем, сообщения о новых релизах любимых исполнителей или чарты треков в жанрах, которые вам нравятся.
Поэтому прогноз, построенный алгоритмом на основе профиля пользователя, мы «разбавляем» информацией из других источников. Это могут быть сведения о том, что слушают друзья из социальных сетей, актуальные подборки — саундтрек к только что вышедшему фильму или сборник композиций, прозвучавших на недавнем музыкальном фестивале, — или списки треков, которые рекомендуют любимые исполнители.

Окончательный список рекомендаций составляется с помощью Матрикснета — разработанного в Яндексе метода машинного обучения. Матрикснет обрабатывает список всех возможных рекомендаций — как полученных прогнозированием, так и составленных по другим источникам — и определяет, какие именно следует показать пользователю на главной странице Яндекс.Музыки и в каком порядке их расположить. Формула, по которой составляется лента рекомендаций, учитывает множество факторов — от сведений о том, сколько раз человек прослушал тот или иной трек, до времени суток: бывает так, что утром нравится одна музыка, а вечером — другая.
***
Задача рекомендаций в Яндекс.Музыке — помогать людям открывать для себя новую музыку. Новую не значит современную — система может посоветовать вам и треки, выпущенные в этом году, и музыку, написанную в XVIII веке. Главное — это будет музыка, которую вы ещё не слышали, но которая вам, скорее всего, понравится.
Яндекс открывает школу дизайна
2015-03-18 14:22:30 (читать в оригинале)В середине июня в Москве открывается Школа дизайна Яндекса — трёхмесячный бесплатный курс о дизайне продуктов в больших компаниях. Занятия ведут сотрудники Яндекса.
yandex.ru/design-school
Идея открыть школу дизайна возникла, когда мы осознали, что рынок полон дизайнерами с хорошим вкусом и поставленной рукой, которым остро не хватает представления о процессах в большой компании, о работе над массовыми продуктами. Когда такие ребята выходят к нам на работу, их многое сбивает с толку: возникает конфликт личности и бренда, количество связей и договоренностей с людьми резко возрастает, а вся творческая энергия поглощается стеной противоречий.В большой компании большие команды. В отличие от мелких групп единомышленников, здесь людям бывает некогда думать о том, как степень их свободы влияет на свободу окружающих. В таких условиях легко потеряться среди «старших». Работа над продуктами, которые создают сотни людей и пользуются которыми миллионы, должна делать из дизайнера ответственного архитектора, а не блуждающего в потёмках.
Преодолению всех этих трудностей мы будем учить студентов нашей школы так, как когда-то учились этому сами.
Мы хотим видеть в школе ребят из всех регионов страны, иногородних привезём и бесплатно поселим недалеко от офиса. Успешных выпускников мы будем рады пригласить на работу.
Заполнить анкету и узнать подробности вы можете на сайте школы.
Команда школы
Итоги всероссийской контрольной по математике
2015-03-16 14:40:34 (читать в оригинале)В день числа «пи», 14 марта, мы провели первую всероссийскую контрольную по математике «Что и требовалось доказать» (ЧТД). За один час нужно было решить десять задач — ну или хотя бы пять, на «тройку».
Всего в контрольной приняли участие более 12,6 тысячи человек из России, Беларуси, Украины, Казахстана и Молдавии. Около четверти из них решили контрольную на «хорошо» и «отлично». В среднем на выполнение десяти заданий участники тратили по 42 минуты, отличники думали немного дольше — по 47—48 минут.
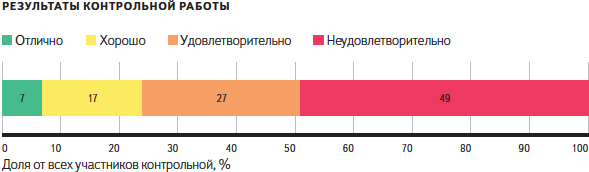
Задачи лучше решали:
— пользователи 21—23 лет (у пользователей из этой группы 35% четвёрок и пятёрок),
— жители Новосибирской области (39% положительных оценок, 12% пятёрок; результаты выше среднего также показали в Татарстане — 38% положительных оценок, Свердловской и Вологодской областях — по 31%),
— мужчины (на четвёрки и пятёрки написали 28% мужчин и 22% женщин).
Самыми простыми задачами оказались наиболее бытовые — про деньги и скидки (стоимость билетов в музей и распродажу лака). Две последние задачи показались участникам сложными — больше половины вообще не дали на них ответа. Вероятно, дело в том, что многим уже не хватило времени, чтобы спокойно вдуматься в условия. А меньше всего правильных ответов дали на задачу № 8 — про электронные часы. Кропотливо пересчитать палочки на электронном табло и перебрать возможные варианты перемены цифр оказалось довольно сложно.

Кстати, порешать задачи контрольной можно и сейчас. Cразу после сдачи ответов вы узнаете свой результат и сможете посмотреть решение каждой задачи.
Контрольная проходила не только в онлайне, но и вузах Москвы, Санкт-Петербурга, Новосибирска, Казани, Нижнего Новгорода, Екатеринбурга, Ростова-на-Дону и Перми. Вот как это было в Екатеринбурге:

В этом году мы проводили «Что и требовалось доказать» впервые. Мы хотели привлечь внимание людей к математике, показать, что это не просто цифры и уравнения, что она развивает умение мыслить структурно и может пригодиться во многих жизненных ситуациях. Судя по отзывам участников, это вполне удалось. Мы хотим проводить ЧТД регулярно и будем рады услышать ваши предложения о том, как нам улучшить контрольную и сделать её ещё более интересной.

Категория «Блогосфера»
Взлеты Топ 5
|
| ||
|
+1241 |
1261 |
Robin_Bad |
|
+1175 |
1263 |
Futurolog |
|
+1090 |
1094 |
MySQL Performance Blog |
|
+1028 |
1098 |
Ksanexx |
|
+1023 |
1097 |
Refinado |
Падения Топ 5
|
| ||
|
-2 |
511 |
партнерки |
|
-3 |
605 |
Блог о раскрутке и монетизации сайта. |
|
-3 |
86 |
Mandalaй.ru |
|
-4 |
17 |
Выводы простого человека |
|
-4 |
39 |
БЛОГика |
Популярные за сутки
Загрузка...
BlogRider.ru не имеет отношения к публикуемым в записях блогов материалам. Все записи
взяты из открытых общедоступных источников и являются собственностью их авторов.
взяты из открытых общедоступных источников и являются собственностью их авторов.