... .jpg" alt='
Explorer 11 теперь ... создало рекламный видеоролик
Explorer 11 ...
... так сказать браузера
Explorer. Если вкратце ...

Вчера я опубликовал топик, в котором описал некоторые удивительные решения, которые приняла компания Майкрософт при выпуске новых версий своего так сказать браузера Internet Explorer. Если вкратце, это:
- введение режимов совместимости со всеми ранее выпущенными версиями браузера вплоть до 5.5;
- решение эмулировать эту совместимость путём тщательного портирирования старых багов;
- отказ от указания имени браузера в юзер-агенте на фоне заявлений о том, что детектировать IE11 по юзер-агенту не надо;
- слом обратной совместистимости между последним Developer Preview и RTM релизом;
- разное поведение, вплоть до падения в некоторых ситуациях, одного и того же браузера под разными версиями операционной системы;
- поддержание глобального списка совместимости, в который попадают те сайты, которые, по мнению Майкрософт, должны показываться в одном из режимов совместимости IE;
- формирование этого списка на основе статистики по кликам пользователей preview-версий браузера в кнопку «Compatibility View»;
- приоритет этого списка над заданной вебмастером метой X-UA-Compatible в RTM-сборке IE11.
Появление этого топика вызвало вал добродушных комментариев, начиная от «автор истеричка» (как будто какой-то из изложенных фактов становится от этого менее весомым) до «Столько бреда, я давно не читал. Смысла даже нет проходиться по всей статье и указывать на ошибки автора». На просьбу таки указать ошибки в изложении было почему-то только отмечено, что последний из приведённых пунктов — а именно, приоритет списка совместимости над X-UA-Compatible — не соответствует действительности (странно, почему же тогда «ошибки» во множественном числе, уважаемый SowingSadness?). Далее в треде от меня потребовали предоставить доказательства этого пункта, заявив, что я либо ошибся, либо просто его придумал.
Хорошо, привожу
После того, как мы сохранили дневник (файлы XML) на компьютер первым или вторым способом, мы можем просматривать их. (Upd: Вот еще способ для браузера Opera, в котором можно скачать сразу все файлы по ссылкам на странице.)
Но, так как изображения в постах размещены на сервере Liveinternet или на других сайтах, куда они загружены, то при отключенном интернет-соединении мы сможем смотреть сохраненные файлы только без изображений. Картинки должны подгружаться на компьютер из Интернета, а они не подгружаются, другими словами.

Чтобы сохранить и картинки на компьютер вместе со страничками, можно преобразовать файлы XML в формат интернет-страниц HTML и пересохранить эти страницы, но уже с изображениями.
Удивительно, но в Сети тяжело найти сервисы или программы, которые перекодируют XML в HTML. Наоборот – сколько угодно, а то, что нам нужно, больше почти никому не надо. Да и сложно это. Поэтому был очень рад найти просто отличную программу Advanced XML Converter. Программа платная, в бесплатной версии она перекодирует и сохраняет только 50% каждого файла. Но, конечно, совсем не трудно найти взломанную умельцами программу.
Конвертация файлов XML в HTML
Сохраните XML-файлы дневника в одну папку. Запустите программу Advanced XML Converter.
В меню программы выберите значок «Open XML» («Открыть XML»). Выберите файл для конвертации. Ниже будет написано, как конвертировать сразу все скаченные файлы, но сначала нужно настроить программу. Хотя, можно и не настраивать…
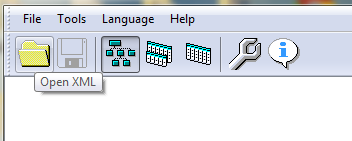
После открытия файла нужно нажать левой кнопкой мыши на ветку «channel». Не знаю, почему именно так, но без простого нажатия на эту строчку файл перекодируется не весь – только заголовок.
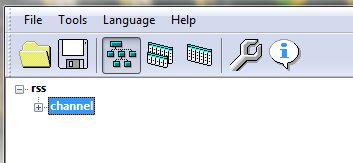
В верхнем меню выбираем «Tools» («Инструменты») и «Field manager» («Менеджер полей»).
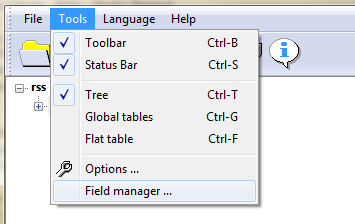
Файлы XML – это по большому счету, особые таблицы, которые состоят из строчек и столбиков с видами данных. Можно перекодировать всю таблицу полностью, а можно удалить некоторые столбцы, которые не нужны для простого чтения записей дневника.
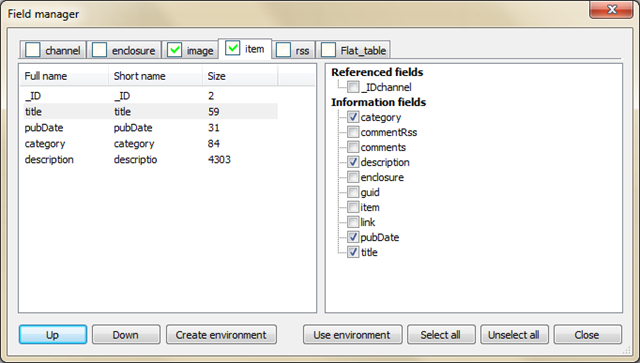
Вы можете выбрать всё, что вашей душе угодно, а дальше рассказано, что сделал я. В верхней части снимите «галочки» со всех вкладок, кроме «image» («изображение») и «item» («элемент»).
На вкладке изображений в правом окошке оставьте только «title» («заголовок») и собственно «image» («изображение»).
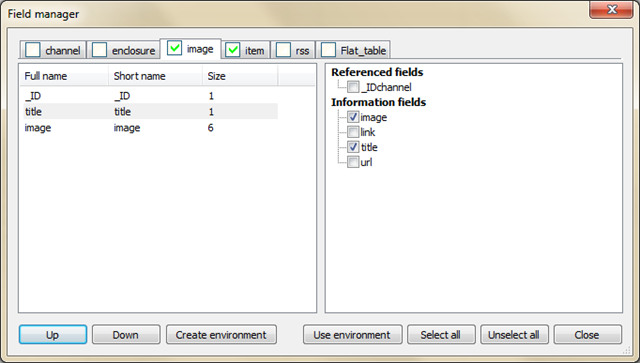
Порядок пунктов в левом окошке можно менять, если нажать на один из них, а затем передвинуть с помощью кнопок «Up» («Вверх») или «Down» («Вниз»). Я расположил так: номер элемента (ID), заголовок и картинка.
То же самое на вкладке «item»: номер, заголовок, дата публикации («pubDate»), рубрика («category») и описание («description»), то есть, в нашем случае – содержание поста.
После этого экспортируем таблицы XML в файл HTML. Нажмите на кнопку «Export tables».
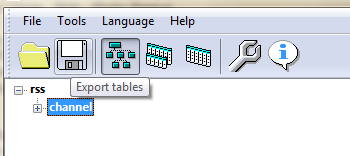
В окне экспорта нужно выбрать «All tables to one output file» («Все таблицы в один файл») или «Every table to own output file» («Каждую таблицу в собственный файл») – удобнее, наверное, всё сохранить одним файлом.
Кнопкой «Browse» выбираем папку сохранения («Destination»), тип файла «File type» – «html: Demo». После этого можно просмотреть, что получится (кнопка «View») или конвертировать файл (кнопка «Convert»).
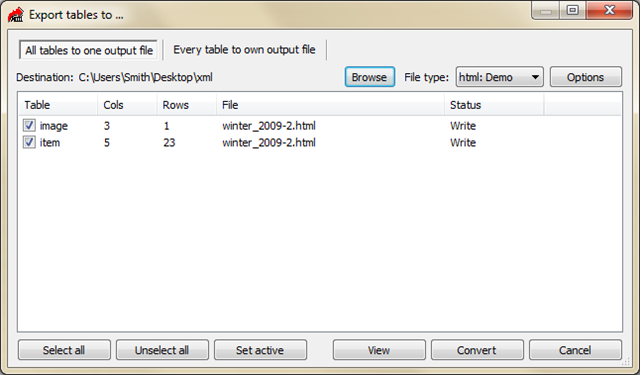
Кстати, кнопка настроек «Options» позволяет указать цвета и границы сохраняемых таблиц.
Также настройки можно найти в главном окне за кнопкой с гаечным ключом «Convert options».
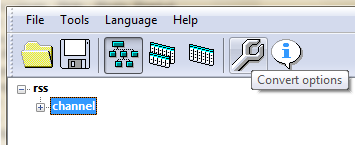
Сохранение дневника на компьютер с картинками
Итак, нажали кнопку «Convert» и через несколько секунд откроется страница в браузере с записями нашего дневника в таблице: номер, заголовок, дата, рубрика, текст поста.
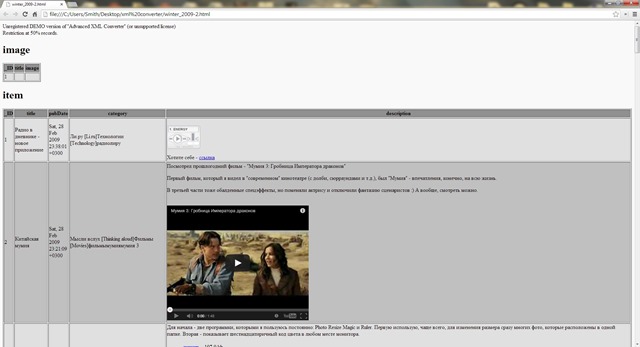
Открытый документ HTML нужно сохранить с вложенными файлами (картинками). Нажимаем известную комбинацию клавиш Ctrl+S и выбираем тип файла «Веб-страница полностью» (в Google Chrome), «HTML-файл с изображениями» (в браузере Opera) и тому подобное. В итоге должен получиться HTML-файл и одноименная папка с картинками и другими файлами. Их нужно всегда держать вместе.
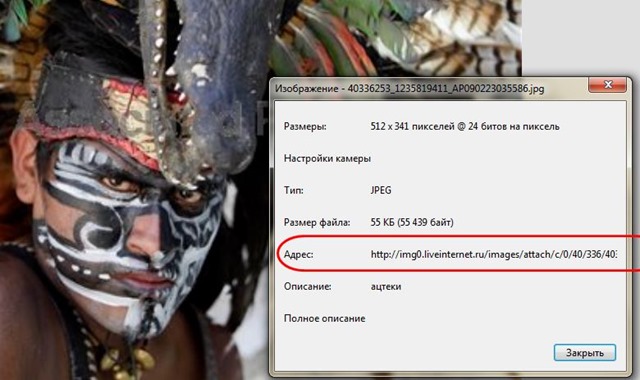
В чем разница? Всё очень просто. Обычный HTML-файл содержит код, где указаны ссылки на изображения. Если в Opera, например, посмотреть свойства этой картинки, то видно, что она загружена на сервер img0.liveinternet.ru и, конечно, будет видна, только если компьютер подключен к Интернету.
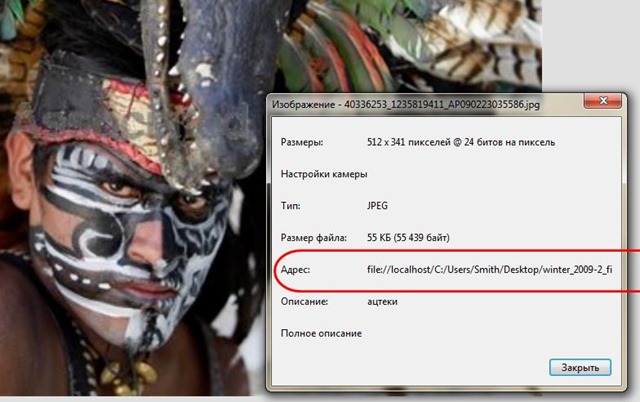
В файле HTML, сохраненном целиком, та же картинка будет иметь такой адрес в свойствах – расположена на локальном компьютере, у нас дома, в общем. Для того, чтобы страничка показала ее, Интернет не нужен.
И напоследок, если в верхнем меню программы выбрать «File» («Файл») – «Convert files from folder» («Конвертировать файлы из папки»), то можно перекодировать сразу все сохраненные XML-файлы с записями дневника.
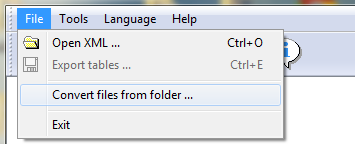
Выберите этот пункт меню, укажите папку-источник (вверху), в один файл или каждый XML в свой HTML (наверное, лучше выбрать свой файл, чтобы браузер не сошел с ума, открывая сразу все страницы дневника), папку назначения, формат выходного файла. Нажать кнопку «Convert» («Конвертировать»).
Удачи! Для тех, кто вообще не раздупляется, написан этот пост.
Скачать программу Advanced XML Converter без 50%-го ограничения конвертации файлов XML в HTML можно в оригинале моего поста (ссылка).
... не только в
Explorer.
Дополнение к предыдущему посту о сохранении дневника в браузере Mozilla Firefox с помощью плагина DownThemAll! Спасибо Ростиславу  Rost за подсказку: «В Опере можно скачивать сразу все файлы по ссылкам со страницы без установки всяких дополнений».
Rost за подсказку: «В Опере можно скачивать сразу все файлы по ссылкам со страницы без установки всяких дополнений».
Для работы пользуюсь Google Chrome, а Opera — в основном, для простого просмотра страниц, поэтому даже не подозревал, что в этом браузере есть такая возможность. Но, кстати, быстро нашел. Для нее существует даже комбинация клавиш, что как бы говорит о важности и полезности.

Кроме того, с обычным сохранением файлов формата XML в Opera есть некоторые затруднения, поэтому возможность пакетной загрузки очень даже хороша.
Как скачать все XML-файлы дневника в браузере Opera
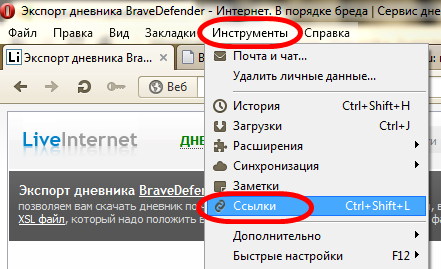
Открываем страницу экспорта дневника. В меню «Инструменты» выбираем «Ссылки» (можно использовать комбинацию клавиш Ctrl+Shift+L).
Открывается вкладка со всеми ссылками, которые браузер нашел на странице. Нажимаем на заголовок столбца «Адрес» для сортировки ссылок по алфавиту. Выбираем все ссылки с расширением .xml (файлы записей дневника) — нажмите левой кнопкой на первую ссылку, нажмите на клавишу Shift, нажмите левой кнопкой на последнюю ссылку, отпустите клавишу Shift.
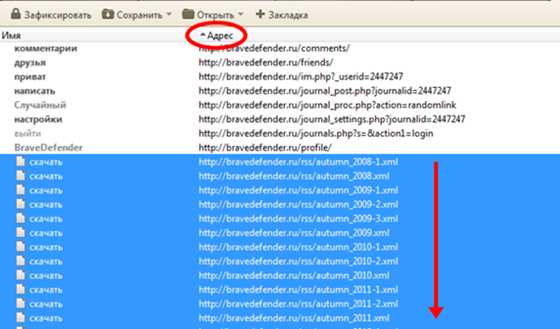
В меню «Сохранить» выбираем «Сохранить в папку загрузки» или «Сохранить по ссылке».
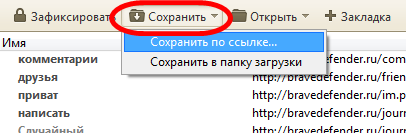
Папка загрузки — это папка, которая у вас установлена для загрузок в браузере Opera. При выборе «Сохранить по ссылке» можно указать папку для загрузки файлов или создать новую.
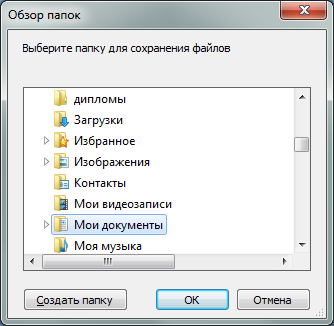
Нажимаем «OK» и браузер начинает загрузку всех выделенных ссылок.
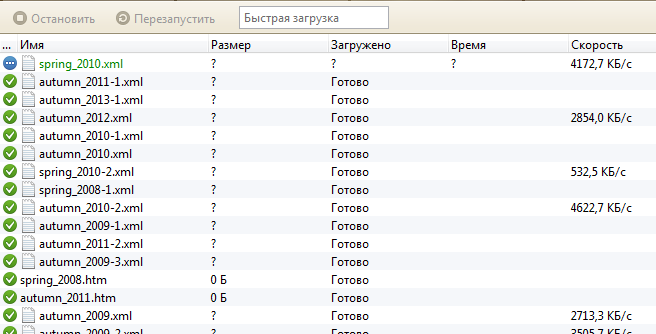
Мир вам!

