Для тех, кто пропустил первую часть статьи: вам сюда. Ну а для всех остальных, как обычно, привет, Хабрахабр. Мы продолжаем тему PWA и изучение базового алгоритма синхронизации (не бросать же начатое?). В прошлой части мы закончили на том, что наше условное приложение умеет запрашивать статьи с сервера, получать только актуальные материалы, следить за изменениями и удалениями статей и грамотно всё это обрабатывать. Работало это всё через вычисление дельты: разницы между тем, что есть у приложения, и тем, что хранится на сервере.
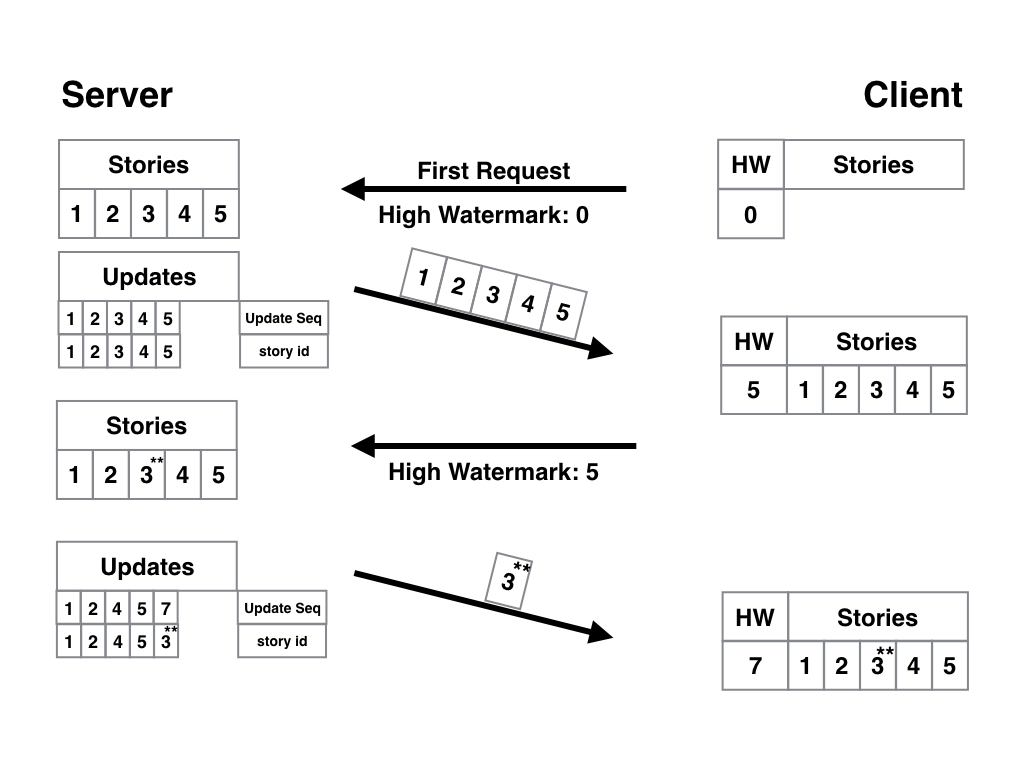
В этой части мы изучим различные конкретные схемы по реализации описанных выше теорий, обсудим их сильные и слабые стороны. Ну а перед тем как мы начнём, давайте опишем требования к искомым алгоритмам.
Читать дальше →