... о неправильной
. Поэтому цитирую ... папку-оператор CodePage (
страниц), справа - ...
В сообществах и комментариях за пару дней видел несколько вопросов о неправильной кодировке. Поэтому цитирую еще раз.
Заходим в пункт "Языки и Региональные Стандарты" в Панели управления и на первой вкладке выбираем "Русский", кроме "Место расположения", далее перемещаемся на последнюю вкладку и в выпадающем списке тоже выбираем "Русский". Перезагружаемся.
Для особых программ, которые почему-то не хотят нормально отображаться, придется внести изменения в реестре.
Следуем по пути Пуск > Выполнить > Registry Editor, там находим HKEY_LOCAL_MACHINE\SYSTEM\ CurrentControlSet\Control\Nls\ CodePage и все значения с 1251 по 1255 модифицируем на одно c_1251.nls.
После этой операции нужно перезагрузиться.
Еще один пост: Как исправить кодировку в поиске Google. Браузер Opera
Картинки для Windows 7
1. Пуск -> Найти... (или Выполнить)
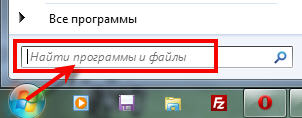
2. Пишем regedit и нажимаем Enter
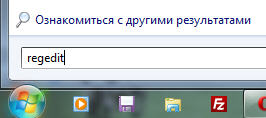
3. Находим в Редакторе реестра нужную ветку
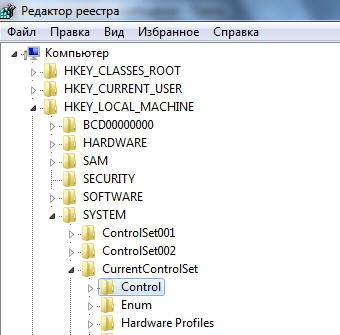
4. Нажимаем на папку-оператор CodePage (кодировка страниц), справа - строковые параметры
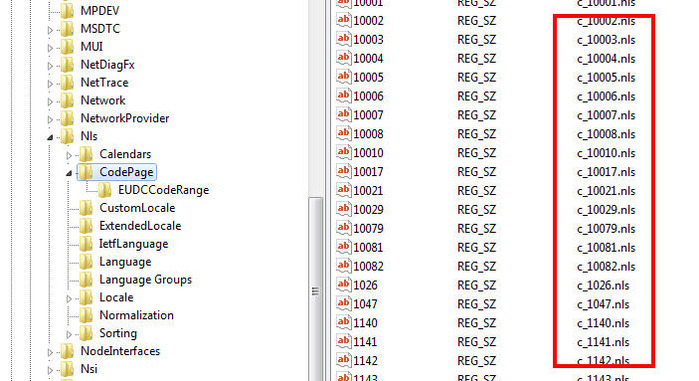
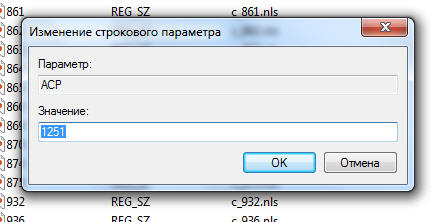
5. Находим нужный, нажимаем на нем правой кнопкой мышки, выбираем Изменить
6. Меняем на нужное, нажимаем OK.
В этом видео представлена информация по основам рынка форекс и базовая терминология.
... проблеме всех питонистов —
. Недавно я получил ...
Данный пост посвящен извечной проблеме всех питонистов — кодировкам. Недавно я получил письмо, в котором мой знакомый жаловался на то, что у него в программе получаются строчки вида::
u'\xd0\x9a\xd1\x83\xd1\x80\xd1\x83\xd0\xbc\xd0\xbe\xd1\x87'
Вы заметили что что-то не так? И я вот. Строчки как бы уникодные, но внутри них закодированные utf-8 байты. Что-то здесь не так. Разбираясь дальше и потребовав скрипт, которые такое генерирует, становится понятно, что данные берутся из веба. Вполне обычным способом через
urllib и потом скармливаются в
lxml.html для разбора. Поскольку
urllib оперирует только байтовыми строками, то он не мог их так превратить в уникод, а значит во всем виноват
lxml.
Читать дальше →
... алгоритм автоматического определения
текста на основе ...
В прошлой статье был реализован алгоритм автоматического определения кодировки текста на основе частот распределения символов. В комментариях отметили: если использовать биграммы (триграммы), результат будет более точный. Тогда я отмахнулся, мол, и на одиночных символах неплохой результат получается. Но сейчас подумал, что неплохо было бы добавить надежности и точности в алгоритм, тем более использование биграмм вместо одиночных символов сильно кушать не просит.
Под катом — пример реализации алгоритма на биграммах, исходники и результаты его работы.
Читать дальше →
... отображаются в неправильной
, вместо символов – ...

Частое явление после переноса сайта на другой хостинг это то, что страницы сайта отображаются в неправильной кодировке, вместо символов – знаки вопроса. Исправить эту проблему мы постараемся следующими способами: Замечу, ... Читать далее...
