2010-01-24 16:09:00
... легко из обычного PDF сделать PDF, легко читаемый ... --margin 5 исходный.pdf обрезанный.pdf + развернуть текстсохранённая копия
Речь пойдёт о том, как отрезать поля (и вообще изменить размер страниц) в PDF-документе. После того, как у меня появилась читалка на электронных чернилах, делать это приходится довольно часто.
В чём проблема: большинство PDF* свёрстаны под печатную страницу формата A4 (29,7×21 см) или Letter, с полями, колонтитулами, всё как положено. А типичный экран читалки — 12×9 см с разрешением 800×600 точек. Даже если показывать по половине странице, на страницу приходится всего 1200×800 точек (и 18×12 см площади экрана). Значит, даже при просмотре страниц «половинками» буквы будут примерно в 1,65 раза мельче, вдобавок и разрешение при этом будет тоже как минимум раза в полтора ниже. Короче говоря, значительная доля PDF, свёрстанных под печать, на нынешних электронных читалка нечитаема.
Впрочем, во многих случаях можно легко из обычного PDF сделать PDF, легко читаемый на экране читалки. Дело в том, что значительную часть площади страницы обычно занимают поля. Они нужны для бумажной версии, но без них вполне можно обойтись на электронной читалке. И если обрезать поля (а в некоторых случаях можно обрезать и колонтитулы), то часто содержательная часть страницы будет выглядеть вполне читаемой и на маленьком экране читалки.
На сегодняшний день я нашёл и попробовал три способа обрезать поля у PDF-файла.
1. Обрезка полей с помощью pdfcrop
Есть скрипт pdfcrop на перле (не путать с одноимённым скриптом на питоне), который умеет обрезать поля автоматически. В Debian он входит в состав пакета texlive-extra-utils.
Советую всегда всё равно оставлять небольшое поле (--margin 5), иначе касающиеся края буквы могут не отображаться на экране читалки.
В общем, всё просто. Преимущества: простой автоматический способ, по полученному таким способом PDF сохраняется возможность поиска. Недостатки такого способа: pdfcrop очень медленно работает с большими документами (сотни страниц), нельзя автоматически отрезать колонтитулы и заметки на полях (в некоторых случаях проще обойтись без номеров страниц и названия главы сверху, зато получить более крупное изображение основного текста), конкретно моя читалка иногда аварийно перегружается на полученных таким способом PDF, на некоторых файлах pdfcrop неправильно определяет границы текста, на некоторых портит шрифты.
2. Растеризация и обрезка страниц в ImageMagick
Пару раз мне пришлось прибегнуть к написанию самодельного скрипта, заточенного под определённый исходный PDF. Общая схема такая:
Исходный PDF → растеризованные изображения страниц (использую pdftoppm) → разрезание страниц на части и обрезка полей (использую convert из ImageMagick) → сборка нового PDF или DjVu из обрезанных страниц.
Вот пример такого скрипта, которым пользуюсь (он не только позволяет разрезать страницы на несколько колонок, но также отрезать поля и пережать, отбросив пустые страницы) — pdf-trim-to-djvu:
Как пользоваться — должно быть ясно из его справки:
Usage: pdf-trim-to-djvu [options] document.pdf
Options: -f the first page to process [default: 1] -t the last page to process -d resolution in DPI [default: 150] -c|--columns multi-column mode [default: 1] --mono bitonal compression (black and white only) --gray DjVuPhoto compression (shades of gray images) [default] --color DjVuPhoto compression (color images) -h|--help print this message
Автоматическая обрезка полей довольно хорошо реализована в команде -trim ImageMagick, но можно задать параметры обрезки и вручную (приходилось). Например, чтобы принудительно обрезать по 3% с каждой стороны, в опции convert можно вставить -shave 3%x3% +repage.
Если хочется не DjVu, а именно PDF, то собрать из изображений PDF можно так (о создании PDF с помощью IM см. здесь):
Если страниц много, такой способ будет очень медленным (и прожорливым), лучше конвертировать каждую отдельно (можно тем же convert, если качество устраивает, можно специально для этих целей предназначенным sam2p), а потом объединять страницы вместе. Для объединения PDF-страниц в PDF-документ я использую pdftk:
$ pdftk *.pdf cat output книжка.pdf
Преимущества этого способа: можно разрезать и обрезать страницы именно так, как надо. Недостатки: возможность поиска по тексту безвозвратно теряется, размер файла обычно увеличивается, добиться нормальной растеризации шрифта трудно, ну и сам скрипт иногда приходится менять под конкретную книжку.
3. Изменение границ страницы в PDFedit
Наконец, есть ещё способ. Совмещающий и возможность указать вручную что именно следует отрезать, и сохраняющий PDF в почти исходном виде. Есть редактор для PDF-файлов — PDFedit. Однако хотя эта программа и с графическим интерфейсом, методы всё те же.
Порядок действий:
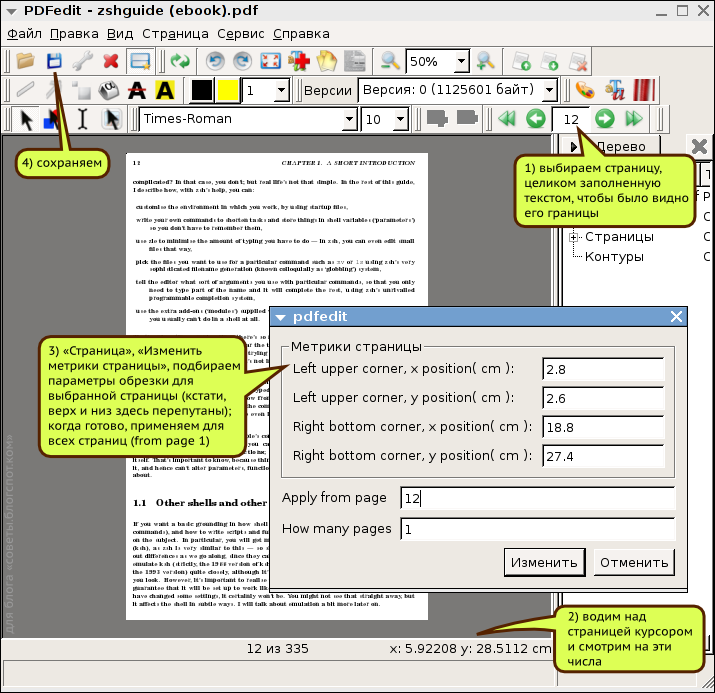
открываем копию PDF-файла в PDFedit и выбираем страницу, целиком заполненную текстом, чтобы было видно его границы;
в меню «Страница» выбираем «Изменить метрики страницы»; далее вводим новые параметры страницы цифрами, жмём «Изменить», чтобы проверить результат (такой вот GUI; что от чего отмеряется придётся познать на опыте), подобрав параметры страницы применяем обрезку ко всем с 1 по последнюю;
сохраняем результат.
Преимущества: способ быстрый (даже если в документе несколько сотен страниц), возможность поиска по тексту сохраняется (да и вообще всё сохраняется), можно как угодно отрезать заметки на полях, номера страниц и колонтитулы. Недостатки: способ требует ручного подбора параметров, нельзя вырезать две страницы из одной (может можно, если дублировать страницы?), сам редактор PDFedit далеко не прост и полон сюрпризов.
* Вот, кстати, не пойму. Современные научные статьи распространяются почти исключительно в электронном виде (бумажные отпечатки — сувениры для авторов). За каждую операцию копирования файла издатели стараются взымать по 30 долларов (думаю, не бедствуют), а вот набирают статьи зачастую таким скупым кеглем, словно свою бумагу жалко. Сравните публикации XIX века и нынешнего. Отчего?
2010-01-24 16:09:00
... легко из обычного PDF сделать PDF, легко читаемый ... --margin 5 исходный.pdf обрезанный.pdf + развернуть текстсохранённая копия
Речь пойдёт о том, как отрезать поля (и вообще изменить размер страниц) в PDF-документе. После того, как у меня появилась читалка на электронных чернилах, делать это приходится довольно часто.
В чём проблема: большинство PDF* свёрстаны под печатную страницу формата A4 (29,7×21 см) или Letter, с полями, колонтитулами, всё как положено. А типичный экран читалки — 12×9 см с разрешением 800×600 точек. Даже если показывать по половине странице, на страницу приходится всего 1200×800 точек (и 18×12 см площади экрана). Значит, даже при просмотре страниц «половинками» буквы будут примерно в 1,65 раза мельче, вдобавок и разрешение при этом будет тоже как минимум раза в полтора ниже. Короче говоря, значительная доля PDF, свёрстанных под печать, на нынешних электронных читалка нечитаема.
Впрочем, во многих случаях можно легко из обычного PDF сделать PDF, легко читаемый на экране читалки. Дело в том, что значительную часть площади страницы обычно занимают поля. Они нужны для бумажной версии, но без них вполне можно обойтись на электронной читалке. И если обрезать поля (а в некоторых случаях можно обрезать и колонтитулы), то часто содержательная часть страницы будет выглядеть вполне читаемой и на маленьком экране читалки.
На сегодняшний день я нашёл и попробовал три способа обрезать поля у PDF-файла.
1. Обрезка полей с помощью pdfcrop
Есть скрипт pdfcrop на перле (не путать с одноимённым скриптом на питоне), который умеет обрезать поля автоматически. В Debian он входит в состав пакета texlive-extra-utils.
Советую всегда всё равно оставлять небольшое поле (--margin 5), иначе касающиеся края буквы могут не отображаться на экране читалки.
В общем, всё просто. Преимущества: простой автоматический способ, по полученному таким способом PDF сохраняется возможность поиска. Недостатки такого способа: pdfcrop очень медленно работает с большими документами (сотни страниц), нельзя автоматически отрезать колонтитулы и заметки на полях (в некоторых случаях проще обойтись без номеров страниц и названия главы сверху, зато получить более крупное изображение основного текста), конкретно моя читалка иногда аварийно перегружается на полученных таким способом PDF, на некоторых файлах pdfcrop неправильно определяет границы текста, на некоторых портит шрифты.
2. Растеризация и обрезка страниц в ImageMagick
Пару раз мне пришлось прибегнуть к написанию самодельного скрипта, заточенного под определённый исходный PDF. Общая схема такая:
Исходный PDF → растеризованные изображения страниц (использую pdftoppm) → разрезание страниц на части и обрезка полей (использую convert из ImageMagick) → сборка нового PDF или DjVu из обрезанных страниц.
Вот пример такого скрипта, которым пользуюсь (он не только позволяет разрезать страницы на несколько колонок, но также отрезать поля и пережать, отбросив пустые страницы) — pdf-trim-to-djvu:
Как пользоваться — должно быть ясно из его справки:
Usage: pdf-trim-to-djvu [options] document.pdf
Options: -f the first page to process [default: 1] -t the last page to process -d resolution in DPI [default: 150] -c|--columns multi-column mode [default: 1] --mono bitonal compression (black and white only) --gray DjVuPhoto compression (shades of gray images) [default] --color DjVuPhoto compression (color images) -h|--help print this message
Автоматическая обрезка полей довольно хорошо реализована в команде -trim ImageMagick, но можно задать параметры обрезки и вручную (приходилось). Например, чтобы принудительно обрезать по 3% с каждой стороны, в опции convert можно вставить -shave 3%x3% +repage.
Если хочется не DjVu, а именно PDF, то собрать из изображений PDF можно так (о создании PDF с помощью IM см. здесь):
Если страниц много, такой способ будет очень медленным (и прожорливым), лучше конвертировать каждую отдельно (можно тем же convert, если качество устраивает, можно специально для этих целей предназначенным sam2p), а потом объединять страницы вместе. Для объединения PDF-страниц в PDF-документ я использую pdftk:
$ pdftk *.pdf cat output книжка.pdf
Преимущества этого способа: можно разрезать и обрезать страницы именно так, как надо. Недостатки: возможность поиска по тексту безвозвратно теряется, размер файла обычно увеличивается, добиться нормальной растеризации шрифта трудно, ну и сам скрипт иногда приходится менять под конкретную книжку.
3. Изменение границ страницы в PDFedit
Наконец, есть ещё способ. Совмещающий и возможность указать вручную что именно следует отрезать, и сохраняющий PDF в почти исходном виде. Есть редактор для PDF-файлов — PDFedit. Однако хотя эта программа и с графическим интерфейсом, методы всё те же.
Порядок действий:
открываем копию PDF-файла в PDFedit и выбираем страницу, целиком заполненную текстом, чтобы было видно его границы;
в меню «Страница» выбираем «Изменить метрики страницы»; далее вводим новые параметры страницы цифрами, жмём «Изменить», чтобы проверить результат (такой вот GUI; что от чего отмеряется придётся познать на опыте), подобрав параметры страницы применяем обрезку ко всем с 1 по последнюю;
сохраняем результат.
Преимущества: способ быстрый (даже если в документе несколько сотен страниц), возможность поиска по тексту сохраняется (да и вообще всё сохраняется), можно как угодно отрезать заметки на полях, номера страниц и колонтитулы. Недостатки: способ требует ручного подбора параметров, нельзя вырезать две страницы из одной (может можно, если дублировать страницы?), сам редактор PDFedit далеко не прост и полон сюрпризов.
* Вот, кстати, не пойму. Современные научные статьи распространяются почти исключительно в электронном виде (бумажные отпечатки — сувениры для авторов). За каждую операцию копирования файла издатели стараются взымать по 30 долларов (думаю, не бедствуют), а вот набирают статьи зачастую таким скупым кеглем, словно свою бумагу жалко. Сравните публикации XIX века и нынешнего. Отчего?
2009-08-26 16:53:00
... же такие PDF открывает, что ... отображения этих PDF нужно поставить кое ... смотреть такие PDF-файлы. + развернуть текстсохранённая копия
Бывают такие PDF, родом из Японии, в которых, если попытаться открыть их в Evince или XPDF — букв вообще не видно, а в Adobe Reader-е вместо букв видны только точки. В свойствах документа список встроенных шрифтов вообще выглядит пустым. Google Docs же такие PDF открывает, что интересно. И открыв такие PDF в Google Docs, можно увидеть, что в них всё таки есть кое-что и латиницей. Только латиница эта — из японских шрифтов (квадратная и широкая).
Оказывается, для отображения этих PDF нужно поставить кое-какие дополнительные пакеты. Для Evince — нужно поставить рекомендуемый пакет poppler-data*. Для XPDF — нужно поставить пакет xpdf-japanese*. И только после этого мы действительно сможем нормально смотреть такие PDF-файлы.
2009-08-26 16:53:00
... же такие PDF открывает, что ... отображения этих PDF нужно поставить кое ... смотреть такие PDF-файлы. + развернуть текстсохранённая копия
Бывают такие PDF, родом из Японии, в которых, если попытаться открыть их в Evince или XPDF — букв вообще не видно, а в Adobe Reader-е вместо букв видны только точки. В свойствах документа список встроенных шрифтов вообще выглядит пустым. Google Docs же такие PDF открывает, что интересно. И открыв такие PDF в Google Docs, можно увидеть, что в них всё таки есть кое-что и латиницей. Только латиница эта — из японских шрифтов (квадратная и широкая).
Оказывается, для отображения этих PDF нужно поставить кое-какие дополнительные пакеты. Для Evince — нужно поставить рекомендуемый пакет poppler-data*. Для XPDF — нужно поставить пакет xpdf-japanese*. И только после этого мы действительно сможем нормально смотреть такие PDF-файлы.
Мы подошли к самому важному - созданию и редактированию PDF-файлов. Некоторые программы в нижеприведенном списке мы уже знаем по предыдущим постам, в которых мы говорили о конвертации в/из PDF. Напомню, что все это на английском, и хотя, по моим понятиям, не представляет большой сложности, но тем не менее, наверное, русскоязычному пользователю гораздо приятнее иметь дело с программами на родном языке. Поэтому повторю свою просьбу: дополняйте ссылками на русскоязычные ресурсы!
скриншот п.12
Онлайн инструменты:
1. - Google Docs является свободным, веб-текстовым процессором, с электронными таблицами, предлагаемым Google. Он позволяет загрузить файл в PDF. 2. - Вы можете создать свой собственный файл с расширением pdf. Регистрация обязательна. 3. - С PDF Hammer можно быстро и легко редактировать файлы в сети, без необходимости устанавливать что-либо. 4. - Бесплатный онлайн PDF создатель. 5. - Онлайн pdf редактор, работает над любой формой. 6. - Ваш онлайн PDF редактор с заполнителем форм и форм-дизайнером. 7.
Оффлайн инструменты:
1. CutePDF Writer - создавайте и редактируйте pdf бесплатно. 2. OpenOffice.org - Свободный и открытый набор, который позволит сохранить документ в PDF. 3. A-PDF INFO Changer - Очень простой инструмент, который позволяет изменить свойства файла PDF, в том числе автора, название, предмет и ключевые слова. Не требует Adobe Acrobat. 4. PDFTools 1.3 - PDFTools является приложением для управления PDF. Оно может шифровать, расшифровывать, присоединять, штамповать, создавать и упорядочивать PDF-файлы. 5. FPDF - является PHP классом, который позволяет создавать файлы PDF с чистым PHP 6. PDF Text Reader - Преобразование PDF файлы в TXT или обратно.