2014-12-10 10:06:07
До конца года осталось меньше месяца. Мы проанализировали поисковые запросы людей и выяснили, какие ...
+ развернуть текстсохранённая копия
До конца года осталось меньше месяца. Мы проанализировали поисковые запросы людей и выяснили, какие темы больше всего волновали их в этом году. В список попали люди, события и явления, которые вызвали всплеск интереса пользователей. Сравните свои ощущения с нашими данными.
Сегодня мы открыли новое направление по работе с «большими данными» — Yandex Data Factory. В рамках YDF компании, которые имеют дело с огромными массивами информации, смогут решать свои задачи с помощью технологий Яндекса.
Чёткого определения у понятия «большие данные» нет. Одно из первых описаний предложили в 2001 году — оно известно как принцип «трёх V». Данные называют большими, если они обладают тремя признаками: большой объём (volume), многообразие (variety) и скорость (velocity). Последнее означает, что данные постоянно обновляются и нуждаются в своевременной обработке.
С «большими данными» имеют дело практически в любой сфере бизнеса: от банковского дела до телекоммуникаций, от коммунального хозяйства до здравоохранения. Компании собирают и хранят множество информации: планы, отчёты, сведения о действиях клиентов, показания датчиков, настройки оборудования, характеристики продукции, видео с камер наблюдения. Эта информация объёмна, разнообразна и зачастую обновляется в режиме реального времени.
Умение анализировать «большие данные» даёт много преимуществ. Выявив закономерности в данных, банк, например, сможет определить, какие продукты предложить клиентам, а поставщик коммунальных услуг — предсказать аномальные всплески потребления горячей воды и подготовиться к ним. Сложность, однако, состоит в том, что для анализа «больших данных» — в силу их объёма и разнородности — необходимы специальные инструменты. Такие инструменты есть у Яндекса.
В число технологий, которые используются для анализа данных в Yandex Data Factory, входят метод машинного обучения Матрикснет, глубокие нейронные сети, распознавание образов и речи, рекомендательные системы. Все они были разработаны Яндексом для собственных нужд — и собственных данных. Матрикснет мы изначально создавали для составления формулы ранжирования в поиске — а потом он стал использоваться и для прогнозирования пробок в Яндекс.Картах, и для таргетинга рекламы в Яндекс.Директе, и для машинного перевода текстов с одного языка на другой в Яндекс.Переводе.
Со временем мы убедились, что наши алгоритмы могут применяться и в отраслях, не связанных с интернетом — так как они не анализируют содержание данных, а выявляют в них закономерности. Первым опытом применения технологий Яндекса в сторонних проектах стало сотрудничество с Европейским центром ядерных исследований (CERN). В частности, Матрикснет лёг в основу системы поиска редких событий — данных о столкновениях частиц — в эксперименте LHCb на Большом адронном коллайдере.
В Яндексе работают очень сильные специалисты по анализу данных. А кроме того, у нас есть система их подготовки. С 2007 года обучением в этой области занимается Школа анализа данных. В 2014 году Яндекс и Высшая школа экономики открыли факультет компьютерных наук, в состав которого входит департамент больших данных и информационного поиска.
Перед публичным запуском Yandex Data Factory мы провели несколько пилотных проектов по обработке «больших данных» с компаниями-партнёрами. В частности, для компании, обслуживающей линии электропередач, в Yandex Data Factory создали систему, которая анализирует сделанные беспилотниками снимки и автоматически выявляет угрозы: например, деревья, растущие слишком близко к проводам. А для автодорожного агентства проанализировали данные о загруженности дорог, качестве покрытия, средней скорости движения транспорта и аварийности. Это позволило в режиме реального времени составлять прогноз заторов на дорогах на ближайший час и выявлять участки с высокой вероятностью ДТП.
Услугами Yandex Data Factory могут воспользоваться как российские, так и зарубежные компании из разных отраслей. Подробности о Yandex Data Factory можно узнать на сайте проекта.
2014-12-05 12:46:21
Осенью прошлого года в Яндекс.Картинках появился поиск по загруженному изображению. Это была первая ...
+ развернуть текстсохранённая копия
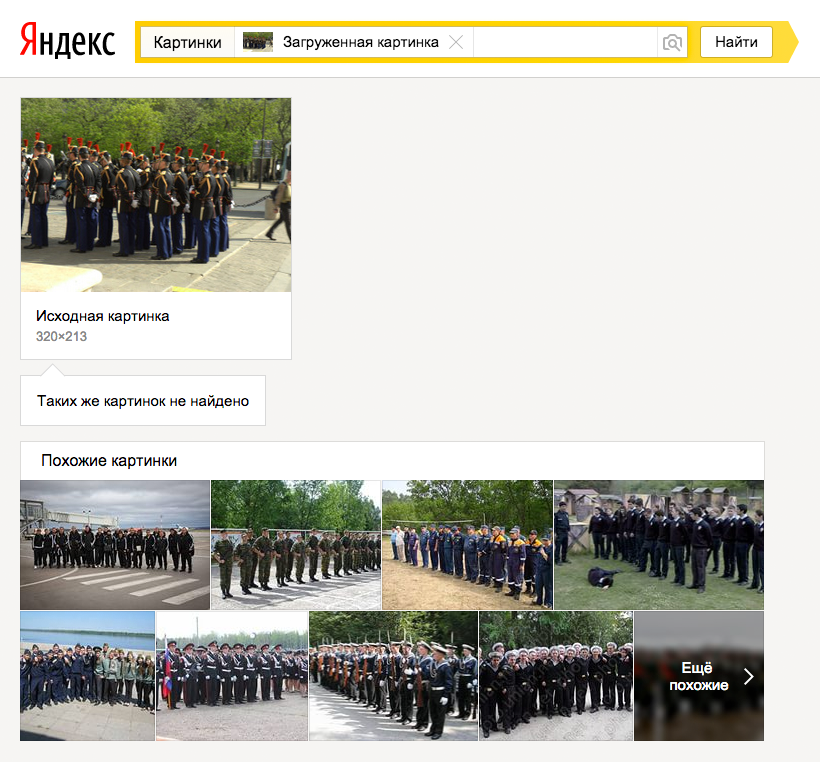
Осенью прошлого года в Яндекс.Картинках появился поиск по загруженному изображению. Это была первая реализация нашей технологии компьютерного зрения «Сибирь». Специальный алгоритм разбивает загруженную картинку на визуальные слова и с их помощью сопоставляет её с миллиардами известных ему изображений, отбирая дубликаты.
Такой подход позволял искать копии картинки или её варианты: например, ту же картинку другого размера или, скажем, без подписей. Однако уже тогда поиск показывал первые способности к обобщению — и в некоторых случаях находил не просто копии загруженной картинки, а другие изображения, содержащие такой же объект.
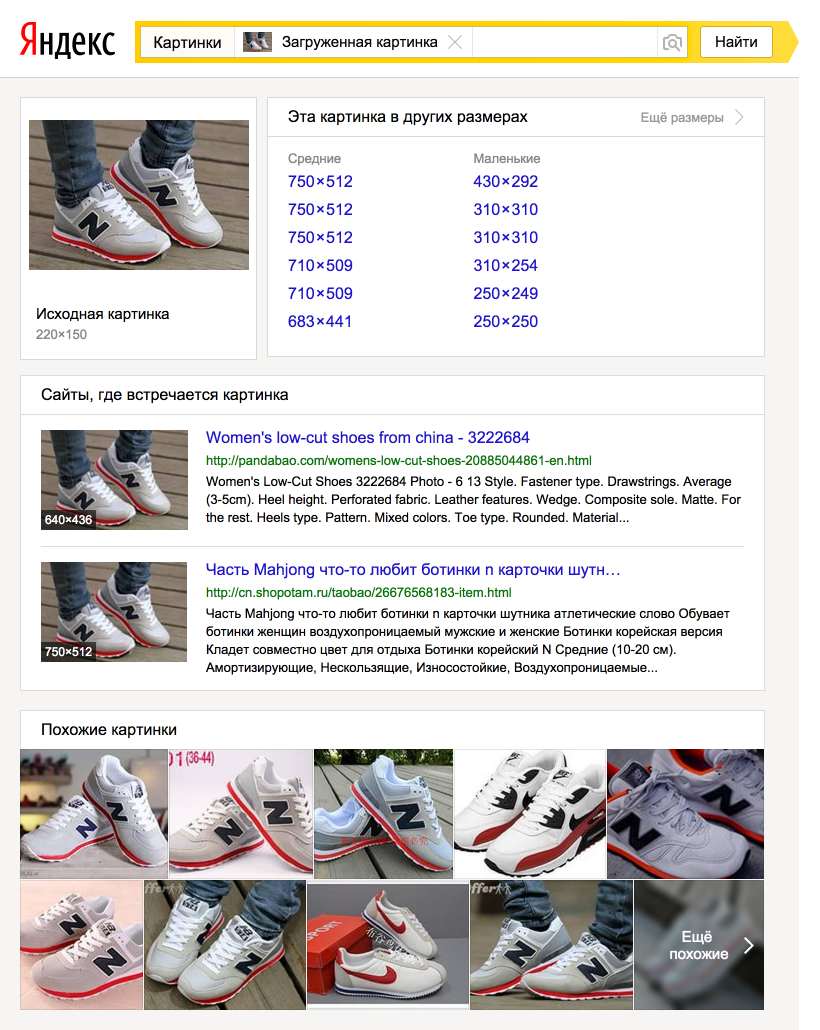
Недавно мы дополнили «Сибирь» технологией, основанной на глубоких нейронных сетях. Благодаря этому в Яндекс.Картинках теперь можно искать не только копии данного изображения, но и похожие на него картинки. Другими словами, вы можете найти не разные варианты самой картинки, но разные варианты того, что на ней изображено. Например:
Такой поиск особенно хорош, когда точных копий загруженного изображения в интернете нет, но похожие на него картинки отлично решают вашу задачу. Например, если вы сфотографировали аллею с уходящими вдаль деревьями, то с помощью Яндекс.Картинок легко можете найти разные варианты таких аллей и выбрать из них подходящую по размеру и качеству картинку, чтобы поставить её на рабочий стол.
Даже если в интернете есть копии загруженной картинки, похожие расширят и дополнят ответ поиска. Скажем, по фотографии кроссовок, загруженной в Яндекс.Картинки, вы найдёте изображения этих кроссовок в разных ракурсах, и, возможно, другие модели, похожие на них.
В интерфейсе сервиса похожие изображения отделены от точных копий. А если копий не нашлось, то Картинки покажут только похожие результаты.
Компьютер «видит» изображения совсем иначе, чем человек, поэтому среди найденных картинок могут оказаться и не совсем, на наш взгляд, похожие. Например, среди фотографий машин, похожих на загруженную, не обязательно будут машины той же марки и модели. В будущем мы надеемся сделать поиск по картинке ещё точнее и научить его давать развёрнутый ответ на ваш запрос, а именно — распознавать и описывать то, что изображено на загруженной картинке.
Каждый день люди спрашивают Яндекс обо всём на свете. Некоторые запросы объединяет какой-то признак: например, тема или форма запроса. Если выбрать запросы с общим признаком, можно узнать, как то или иное явление отражается в поиске Яндекса. Время от времени мы так и делаем, и тогда на свет появляются поисковые исследования. Сегодня мы опубликовали очередное исследование — о том, на кого хотят быть похожи пользователи поиска.
В сентябре и октябре 2014 года люди задали Яндексу более 500 тысяч запросов со словами «как у»: [часы как у Путина], [зубы как у звёзд], [глаза как у вампира], [бутсы как у Месси] и многие-многие другие. Мы проанализировали эти запросы и выяснили, какие предметы, атрибуты, люди и персонажи пользуются в поиске наибольшей популярностью.
Почти две трети запросов касаются конкретных людей или персонажей — в основном это актёры, телеведущие и спортсмены. Чаще всего люди ищут то, что легко купить или повторить: причёски, макияж, одежду, татуировки и так далее.
Среди всех персонажей и людей, на которых хотят быть похожи авторы поисковых запросов, мы выделили самых популярных. У мужчин лидируют Криштиану Роналду, Владимир Путин и герой Дмитрия Нагиева из сериала «Физрук». У женщин — телеведущие Ксения Бородина и Ольга Бузова, а также Виолетта из одноимённого сериала.
Больше подробностей ищите на странице исследования.
2014-12-04 09:46:27
Протестировал защищенный телефон teXet TM 511R. Из плюсов – заряжаю раз в месяц. Функционал ...
+ развернуть текстсохранённая копия
Протестировал защищенный телефон teXet TM 511R. Из плюсов – заряжаю раз в месяц. Функционал небольшой, но практичный, потому не потребляет много энергии. А при емкости 2700 мА-ч батареи реально хватает на 30 дней. В общем, заряжаю автоматом первого числа каждого месяца, для чего поставил напоминание (с teXet TM 511R начал забывать, что гаджеты нуждаются в энергии).