Какой рейтинг вас больше интересует?
|
Главная / Главные темы / Тэг «intrend»

Парсинг HTML-страниц на примере Yandex.Маркет (с HtmlAgilityPack) 2012-10-19 09:07:35
 + развернуть текст сохранённая копия
+ развернуть текст сохранённая копия

Довольно часто возникает ситуация, когда в автоматическом режиме нужно получить какие-то данные со страницы в формате HTML или XHTML. Парсить можно разными способами, используя встроенные в Framework средства или сторонние библиотеки.
На сегодняшний день мне известны два способа парсинга:
с помощью регулярных выражений;
с помощью XPath.
В данной статье разберем, как можно использовать XPath для получения нужного текста.
Предположим, что нам необходимо получить характеристики товара со страницы http://market.yandex.ua/model-spec.xml?modelid=7911905&hid=90639.
Первая часть работы — получение html-текста страницы. Как вы его получите, — это уже второй вопрос или через WebClient, компонент браузера или загрузите файл с жесткого диска.
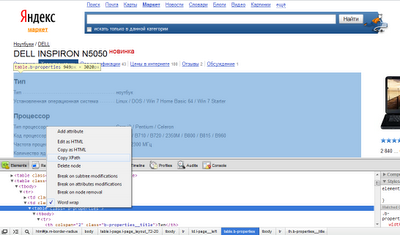
Вторая часть работы сводится собственно к парсингу нужного текста. Для начала нам необходимо получить XPath к заданном элементу в структуре HTML или XHTML. Чтобы не писать все руками, открываем браузер Chrome или Firefox с плагином Firebug. В браузере F12 и попадаем в исходный код страницы. Выбираем искомый элемент и нажимаем правую кнопку мыши. В выпадающем меню выбираем Copy XPath. В Firefox по аналогии.
В результате в буфере обмена будет текст (для Chrome):
//*[@id="js"]/body/table[3]/tbody/tr/td[2]/table
Firefox:
/html/body/table[3]/tbody/tr/td[2]/table
В этом тексте описан полный путь к элементу. Но, здесь есть нужно кое-что изменить. Во первых всегда нужно убирать tbody., во вторых нет необходимости писать html или *[@id="js"], в случае с Chrome.
Нам достаточно строки:
//body/table[3]/tr/td[2]/table
Теперь берем библиотеку HtmlAgilityPack и скармливаем ей наш путь и исходный текст страницы следующим образом:
public string GetDescription(string html)
{
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
doc.OptionFixNestedTags = true; //Опционально, если требуется
doc.Load(new StringReader(html));
HtmlNode node = doc.DocumentNode.SelectSingleNode("//body/table[3]/tr/td[2]/table");
return node.OuterHtml;
}
В данном случае мы передаем тело html-страницы и через SelectSingleNode получаем исходный код таблицы. Обратите внимание, чтобы получить html-код найденной таблицы, необходимо использовать свойство OuterHtml. Свойство InnerHtml вернет чистый текст без тегов. Таким образом, мы на выходе метода получим таблицу, которую можно разобрать и обработать.
Все остальные данные по товару получаем по схожей схеме.
Источник http://krez0n.org.ua

Тэги: form, internet, web, window
Автозаполнение в WebBrowser 2012-10-19 08:48:54
 + развернуть текст сохранённая копия
+ развернуть текст сохранённая копия

Данный пример показывает как легко и просто можно реализовать авто заполнение в компоненте WebBrowser. Мне данный пример пригодился для авто заполнения формы и автоматической регистрации на сайте www.masterlike.ru
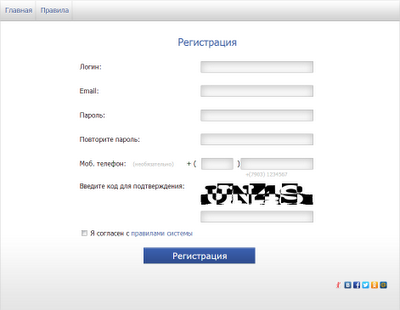
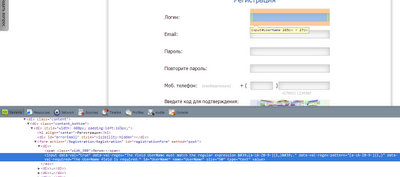
Для работы нам понадобится разместить компонент WebBrowser на форму! Теперь буду пытаться объяснить как выполнить данную задачу на примере сайта www.masterlike.ru. Вот так у него выглядит форма регистрации:
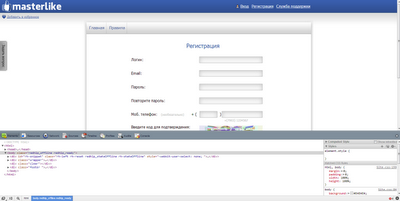
Давайте подробнее рассмотрим что мы можем здесь заполнить автоматически, это будут все поля кроме поля ввода кода подтверждения так как он всегда разный! Теперь необходимо определить имена полей которые мы заполняем, для этого открываем браузер Chrome и переходим на нашу страничку www.masterlike.ru,после полной загрузки страницы нажимаем "F12". У нас появится дополнительное окно:
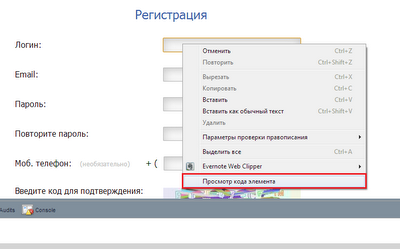
Далее нам необходимо узнать ID первого текстового поля, ввода Логин. Для это правой клавишей мыши нажимаем на это текстовое поле и выбираем пункт "Просмотр кода элемента".
После этого мы увидим код необходимого нам текстового поля.
В этом коде нам необходим всего лишь один параметр, это id компонента:
input data-val-regex-pattern="[a-zA-Z0-9-]{1,}" data-val-regex="The field UserName must match the regular expression '[a-zA-Z0-9-]{1,}'." data-val-required="The UserName field is required." data-val="true" id="UserName" name="UserName" size="50" type="text" value=""
Для поля ввода "Логин" это будет "UserName". Теперь его необходимо заполнить:
webBrowser1.Document.GetElementById("UserName").SetAttribute("value", "csharpcoderr");
В примере выше мы извлекли отдельный объект System.Windows.Forms.HtmlElement с использованием атрибута ID GetElementById("UserName") этого элемента в качестве поискового ключа и задали значение атрибута с заданным именем(value) в элементе.
С остальными полями поступаете так же. Единственное что нам осталось это поставить галочку "Я согласен с правилами системы". Для это мы выполняем все те же действия как и для текстового поля и получаем ID нашего checkbox.
HtmlDocument rememberme = this.webBrowser1.Document;
rememberme.GetElementById("helpbox").SetAttribute("checked", "true");
Думаю здесь мне уже не надо ничего обьяснять. Вот полный пример кода для заполнения формы регистрации сайта www.masterlike.ru
private void button1_Click(object sender, EventArgs e)
{
if (webBrowser1.ReadyState == WebBrowserReadyState.Complete)
{
webBrowser1.Document.GetElementById("UserName").SetAttribute("value", "csharpcoderr");
webBrowser1.Document.GetElementById("Email").InnerText = "info@csharpcoderr.com";
webBrowser1.Document.GetElementById("Password").InnerText = "11111111";
webBrowser1.Document.GetElementById("ConfirmedPassword").InnerText = "11111111";
webBrowser1.Document.GetElementById("Phonecode").InnerText = "7922";
webBrowser1.Document.GetElementById("Phone").InnerText = "7946455";
HtmlDocument rememberme = this.webBrowser1.Document;
rememberme.GetElementById("helpbox").SetAttribute("checked", "true");
}
}

Тэги: form, internet, web, window
Справедливость или пузомерки? О там, как ТиЦ и PR затмевают головы вебмастерам 2012-10-18 16:50:59
 + развернуть текст сохранённая копия
+ развернуть текст сохранённая копия
Просьба всех веб-мастеров, и лиц, причисляющих себя к оным, отойти от компьютера или закрыть вкладку браузера. Человек, далекий от веб-технологий будет рассуждать о справедливости и прочих высоких материях;)
Тэги: internet, показатель, сайт, тиц
Website SEO Secret Tips Uncovered 2012-10-17 22:27:10
A study conducted several years ago revealed that 93 percent of web users do not look beyond the ...
+ развернуть текст сохранённая копия
A study conducted several years ago revealed that 93 percent of web users do not look beyond the first page of search results. This only reaffirms the belief that competition in terms of relevance in the World Wide Web is indeed tough and this is the reason why lots of companies are making sure that [...]
Тэги: advertising, business, categorized, company, engine, home, internet, local, market, online, optimization, search, sem, seo
IE10 выйдет для Windows 7 в ноябре 2012-10-17 22:16:55
Microsoft выпустит IE10 для Windows 7 в ноябре этого года.
Тэги: explore, internet
Главная / Главные темы / Тэг «intrend»
|
Взлеты Топ 5
Падения Топ 5
|