| Сегодня 6 апреля, понедельник |
|
|
|
Какой рейтинг вас больше интересует?
|
Главная /
Каталог блоговCтраница блогера CODE1NSTINCT/Записи в блоге |
Эластичный MapReduce. Распределенная реализация
2012-09-19 13:09:00 (читать в оригинале)Распределенное введение в эластичные проблемы Hadoop
Симбиоз облачных технологий и платформы Apache Hadoop уже не первый год рассматривается как источник интересных решений, связанных с анализом Big Data.
И основной момент, почему именно «симбиоз», а не «чистый» Hadoop – это, конечно, снижение уровня входа для разработчиков MPP-приложений (и не только) как с точки зрения квалификации (администратора), так и первоначальных финансовых вложений в аппаратную часть, на которой приложение будет исполняться.
Второй момент – это то, что облачные провайдеры смогут обойти некоторые ограничения Hadoop*, навязанные архитектурой master/slave (master всегда единичная точка отказа и с этим надо что-то делать) и, возможно (на Microsoft, в связи с параллельно развивавшимся проектом Dryad, была особая надежда), даже сильным сцеплением хранилища данных (HDFS) и компонентами выполнения распределенных вычислений (Hadoop MapReduce).
Надежды, относящиеся к первому пункту - снижение стоимости владения Hadoop-кластером - оправдались более чем: крупнейшая тройка облачных провайдеров, с разностью степенью близости к release-mode, начали предоставлять «Hadoop-кластер as a Service» (терминология моя и условная) за цены, вполне «подъемные» для стартапов и/или исследовательских групп.
Надежды же, связные с обходом ограничений платформы Hadoop, не сбылись вовсе.
Amazon Web Services, как и IaaS-платформа, никогда и не стремилась предоставлять услуги как сервис (хотя и тут есть исключение – Amazon S3, Amazon DynamoDB). И в далеком 2009 году компания Amazon предоставила разработчикам сервис Amazon Elastic MapReduce как инфраструктуру, а не как сервис.
Вслед за Amazon в середине 2010 года компания Google анонсировала экспериментальную версию программного интерфейса App Engine MapReduce, в рамках своей облачной платформы Google App Engine.
App Engine MapReduce API предоставил разработчикам «Hadoop MapReduce»-подобные интерфейсы к своим, уже работающим по парадигме map/reduce, службам. Но это никак не убрало ограничений сильной связанности хранилища данных и компонентов вычислений. Более того, сам Google добавил туда ограничений - возможности переопределения только map-фазы**, да и сама платформа GAE, со свойственными ей квотами, наложила (как я подозреваю) еще пару ограничений на App Engine MapReduce API.
В 2011 года очередь дошла до Microsoft. В октябре 2011 года Microsoft объявила об открытии сервиса Hadoop on Azure. На текущий момент времени он находится в CTP-версии. Попробовать у меня этот сервис из-за отсутствия приглашения (и наличия лени) не получилось. Но, по отсутствию статей о преодоленных ограничениях Hadoop, понятно, что «проблемы» платформы Hadoop и в этом случае оставили решать самой Hadoop.
Описанные выше ограничения решений на основе «облачных платформ + Hadoop» позволяют понять круг проблем, решаемых проектом Cloud MapReduce, речь о котором и пойдет далее.
Облачная экосистема Amazon Web Services
2012-09-02 16:19:00 (читать в оригинале) Amazon Web Services (AWS) – это публичная облачная платформа, предоставляемая компанией Amazon. AWS – относится к классу IaaS-решений и предоставляет широкий спектр облачных сервисов.
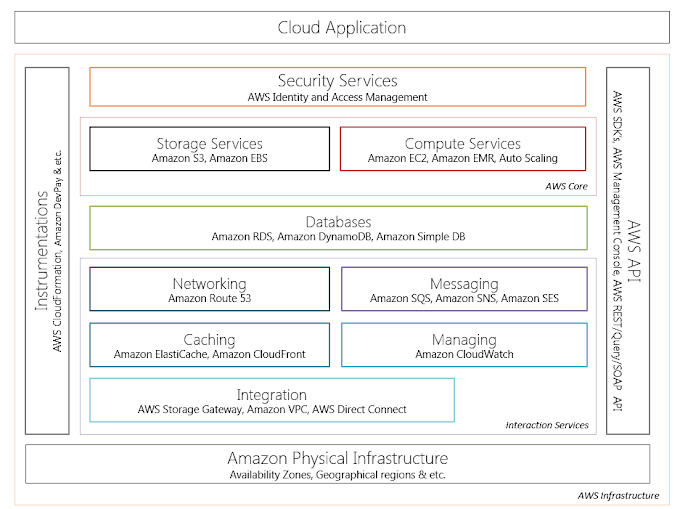 Список облачные сервисов AWS на сентябрь 2012 года представлен в ниже.
Список облачные сервисов AWS на сентябрь 2012 года представлен в ниже.
Hadoop save the World? (Платформа Hadoop. Заключение)
2012-08-19 16:32:00 (читать в оригинале) В последней части цикла про Hadoop поговорим о том, насколько платформа Hadoop является «серебряной пулей» в мире распределенных вычислений; о спектре решаемых ею задач и ограничениях платформы и о критике и перспективах платформы.

Содержание цикла:
ограничения HDFS и ограничения Hadoop MapReduce), так и ограничений собственно самой платформы. - Введение. Big Data in the Cloud
- 1. Платформа Hadoop. Обзор
- 2. HDFS. Основные концепции и архитектура
- 3. Hadoop MapReduce. Основные концепции и архитектура
- Заключение. Hadoop Save The World?!
- Список источников
Hadoop MapReduce. Основные концепции и архитектура (Платформа Hadoop. Часть 3)
2012-08-19 16:26:00 (читать в оригинале)Программная модель map/reduce
Выполнение распределенных задач на платформе Hadoop происходит в рамках парадигмы map/reduce*.
map/reduce – это парадигма (программная модель) выполнения распределенных вычислений для больших объемов данных.
В общем случае, для map/reduce выделяют 2 фазы:
Читать полностью
- map(ƒ, c)
Принимает функцию ƒ и список c. Возвращает выходной список, являющийся результатом применения функции ƒ к каждому элементу входного списка c.")
- reduce(ƒ, c)
Принимает функцию ƒ и список c. Возвращает объект, образованный через свертку коллекции c через функцию ƒ.")
Программная модель map/reduce была позаимствована из функционального программирования, хотя в реализации Hadoop и имеет некоторые семантические отличия от прототипа в функциональных языках.
HDFS. Основные концепции и структура (Платформа Hadoop. Часть 2)
2012-08-12 19:57:00 (читать в оригинале)Одним из ключевых компонентов платформы Hadoop является файловая система HDFS.
Hadoop Distributed File System (HDFS) - распределенная файловая система, которая обеспечивает высокоскоростной доступ к данным приложения.
Концепции и структура HDFS
HDFS является иерархической файловой системой. Таким образом, в HDFS имеется поддержка вложение каталогов. В каталоге может располагаться ноль или более файлов, а также любое количество подкаталогов.
HDFS состоит из следующих обязательных компонентов:
- Узел имен (NameNode) – программный код, выполняющийся, в общем случае, на выделенной машине экземпляра HDFS и отвечающий за файловые операции (работу с метаданными);
- Узел данных (DataNode) – программный код, как правило, выполняющийся выделенной машине экземпляра HDFS и отвечающий за операции уровня файла (работа с блоками данных).
Hadoop содержит единственный узел типа NameNode и произвольное количество узлов типа DataNode.
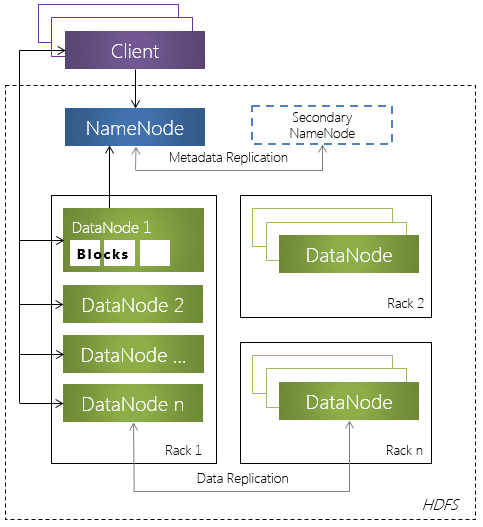
Основные концепции, заложенные при проектировании HDFS, и архитектурные решения, применяемые для реализации этих концепций, приведены ниже:

Категория «Образование»
Взлеты Топ 5
|
| ||
|
+493 |
506 |
В интересном положении |
|
+450 |
511 |
Документальное кино |
|
+439 |
471 |
ГОРОСКОП |
|
+406 |
514 |
Документальные фильмы |
|
+377 |
445 |
Темы_дня |
Падения Топ 5
|
| ||
|
-1 |
13 |
Волонтеры. Красный крест |
|
-1 |
30 |
Skytao |
|
-3 |
8 |
Улицы Праги |
|
-7 |
5 |
Планирование проекта |
|
-8 |
6 |
Адреналин продаж |
Популярные за сутки
Загрузка...
BlogRider.ru не имеет отношения к публикуемым в записях блогов материалам. Все записи
взяты из открытых общедоступных источников и являются собственностью их авторов.
взяты из открытых общедоступных источников и являются собственностью их авторов.